A recurrent neural network (RNN) is a class of artificial neural network where connections between nodes form a directed graph along a sequence. This allows it to exhibit temporal dynamic behavior for a time sequence. Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs.
I am showing a basic implementation of a RNN in DL4J. Further information can be found at
https://deeplearning4j.org/docs/latest/deeplearning4j-nn-recurrent.
This demo has been implemented in Scala using Jupyter with the BeakerX kernel.
Setup
We add the necessary dependencies to the classpath and we import the classes which we subsequently plan to use.
– deeplearning4j-core
– nd4j (which is used for the underlying data model)
– the DeeplearningforJ UI and Logback which is needed by the the UI
%%classpath add mvn
org.nd4j:nd4j-native-platform:1.0.0-beta2
org.deeplearning4j:deeplearning4j-core:1.0.0-beta2
org.deeplearning4j:deeplearning4j-ui_2.11:1.0.0-beta2
ch.qos.logback:logback-classic:1.2.3
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration.ListBuilder;
import org.deeplearning4j.nn.conf.layers.LSTM;
import org.deeplearning4j.nn.conf.layers.RnnOutputLayer;
import org.deeplearning4j.nn.conf.layers.recurrent.SimpleRnn;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.ui.api.UIServer
import org.deeplearning4j.ui.storage.InMemoryStatsStorage
import org.deeplearning4j.ui.stats.StatsListener
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.api.ops.impl.indexaccum.IMax;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.AMSGrad;
import org.nd4j.linalg.learning.config.RmsProp;
import org.nd4j.linalg.lossfunctions.LossFunctions.LossFunction;
import java.util.ArrayList;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Random;
import java.util.Arrays
import org.deeplearning4j.nn.conf.MultiLayerConfiguration
import org.deeplearning4j.nn.conf.NeuralNetConfiguration
import org.deeplearning4j.nn.conf.NeuralNetConfiguration.ListBuilder
import org.deeplearning4j.nn.conf.layers.LSTM
import org.deeplearning4j.nn.conf.layers.RnnOutputLayer
import org.deeplearning4j.nn.conf.layers.recurrent.SimpleRnn
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork
import org.deeplearning4j.nn.weights.WeightInit
import org.deeplearning4j.optimize.listeners.ScoreIterationListener
import org.deeplearning4j.ui.api.UIServer
import org.deeplearning4j.ui.storage.InMemoryStatsStorage
import org.deeplearning4j.ui.stats.StatsListener
import org.nd4j.linalg.activations.Activation
import org.nd4j.linalg.api.ndarray.INDArray
import org.nd4j.linalg.api.ops.impl.i...
Data Model – Character Encoding
We define the sentence to learn as String. A special character is added at the beginning so the RNN learns the complete string and ends with the marker.
We also create a dedicated List of possible chars in the charList variable
val learnString = "*A computer will do what you tell it to do, but that may be much different from what you had in mind.";
val charList = learnString.toSet.toList
[[e, *, n, ., y, t, u, f, A, a, m, i, , ,, b, l, p, c, h, r, w, o, d]]
We use this character list to encode the characters in an ND4 array:
var nd4Array = Nd4j.zeros(1, charList.size, 1)
[[0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0]]
We determine the index position of the character which we want to represent
var pos:Int = charList.indexOf('A')
8
And then we set the corresponding index position in the array to 1
nd4Array.putScalar(pos, 1)
[[0,
0,
0,
0,
0,
0,
0,
0,
1.0000,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0]]
Definition of Neural Network
We define the network architecture: It consists of subsequent LSTM (Long/Short Term Memory) Layers followed by a RnnOutputLayer
import org.nd4j.linalg.learning.config._
// RNN dimensions
val HIDDEN_LAYER_WIDTH = 100;
// some common parameters
var conf = new NeuralNetConfiguration.Builder()
.seed(123)
.biasInit(0)
.miniBatch(false)
.updater(new RmsProp(0.001))
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, new LSTM.Builder()
.nIn(charList.size)
.nOut(HIDDEN_LAYER_WIDTH)
.activation(Activation.TANH)
.build())
.layer(1, new LSTM.Builder()
.nIn(HIDDEN_LAYER_WIDTH)
.nOut(HIDDEN_LAYER_WIDTH)
.activation(Activation.TANH)
.build())
.layer(2, new LSTM.Builder()
.nIn(HIDDEN_LAYER_WIDTH)
.nOut(HIDDEN_LAYER_WIDTH)
.activation(Activation.TANH)
.build())
.layer(3, new RnnOutputLayer.Builder(LossFunction.MCXENT)
.activation(Activation.SOFTMAX)
.nIn(HIDDEN_LAYER_WIDTH)
.nOut(charList.size)
.build())
.pretrain(false)
.backprop(true)
.build()
// create network
var net = new MultiLayerNetwork(conf)
conf
{
"backprop" : true,
"backpropType" : "Standard",
"cacheMode" : "NONE",
"confs" : [ {
"cacheMode" : "NONE",
"epochCount" : 0,
"iterationCount" : 0,
"layer" : {
"@class" : "org.deeplearning4j.nn.conf.layers.LSTM",
"activationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationTanH"
},
"biasInit" : 0.0,
"biasUpdater" : null,
"constraints" : null,
"dist" : null,
"distRecurrent" : null,
"forgetGateBiasInit" : 1.0,
"gateActivationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationSigmoid"
},
"gradientNormalization" : "None",
"gradientNormalizationThreshold" : 1.0,
"idropout" : null,
"iupdater" : {
"@class" : "org.nd4j.linalg.learning.config.RmsProp",
"epsilon" : 1.0E-8,
"learningRate" : 0.001,
"rmsDecay" : 0.95
},
"l1" : 0.0,
"l1Bias" : 0.0,
"l2" : 0.0,
"l2Bias" : 0.0,
"layerName" : "layer0",
"nin" : 23,
"nout" : 100,
"pretrain" : false,
"weightInit" : "XAVIER",
"weightInitRecurrent" : null,
"weightNoise" : null
},
"maxNumLineSearchIterations" : 5,
"miniBatch" : false,
"minimize" : true,
"optimizationAlgo" : "STOCHASTIC_GRADIENT_DESCENT",
"pretrain" : false,
"seed" : 123,
"stepFunction" : null,
"variables" : [ ]
}, {
"cacheMode" : "NONE",
"epochCount" : 0,
"iterationCount" : 0,
"layer" : {
"@class" : "org.deeplearning4j.nn.conf.layers.LSTM",
"activationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationTanH"
},
"biasInit" : 0.0,
"biasUpdater" : null,
"constraints" : null,
"dist" : null,
"distRecurrent" : null,
"forgetGateBiasInit" : 1.0,
"gateActivationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationSigmoid"
},
"gradientNormalization" : "None",
"gradientNormalizationThreshold" : 1.0,
"idropout" : null,
"iupdater" : {
"@class" : "org.nd4j.linalg.learning.config.RmsProp",
"epsilon" : 1.0E-8,
"learningRate" : 0.001,
"rmsDecay" : 0.95
},
"l1" : 0.0,
"l1Bias" : 0.0,
"l2" : 0.0,
"l2Bias" : 0.0,
"layerName" : "layer1",
"nin" : 100,
"nout" : 100,
"pretrain" : false,
"weightInit" : "XAVIER",
"weightInitRecurrent" : null,
"weightNoise" : null
},
"maxNumLineSearchIterations" : 5,
"miniBatch" : false,
"minimize" : true,
"optimizationAlgo" : "STOCHASTIC_GRADIENT_DESCENT",
"pretrain" : false,
"seed" : 123,
"stepFunction" : null,
"variables" : [ ]
}, {
"cacheMode" : "NONE",
"epochCount" : 0,
"iterationCount" : 0,
"layer" : {
"@class" : "org.deeplearning4j.nn.conf.layers.LSTM",
"activationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationTanH"
},
"biasInit" : 0.0,
"biasUpdater" : null,
"constraints" : null,
"dist" : null,
"distRecurrent" : null,
"forgetGateBiasInit" : 1.0,
"gateActivationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationSigmoid"
},
"gradientNormalization" : "None",
"gradientNormalizationThreshold" : 1.0,
"idropout" : null,
"iupdater" : {
"@class" : "org.nd4j.linalg.learning.config.RmsProp",
"epsilon" : 1.0E-8,
"learningRate" : 0.001,
"rmsDecay" : 0.95
},
"l1" : 0.0,
"l1Bias" : 0.0,
"l2" : 0.0,
"l2Bias" : 0.0,
"layerName" : "layer2",
"nin" : 100,
"nout" : 100,
"pretrain" : false,
"weightInit" : "XAVIER",
"weightInitRecurrent" : null,
"weightNoise" : null
},
"maxNumLineSearchIterations" : 5,
"miniBatch" : false,
"minimize" : true,
"optimizationAlgo" : "STOCHASTIC_GRADIENT_DESCENT",
"pretrain" : false,
"seed" : 123,
"stepFunction" : null,
"variables" : [ ]
}, {
"cacheMode" : "NONE",
"epochCount" : 0,
"iterationCount" : 0,
"layer" : {
"@class" : "org.deeplearning4j.nn.conf.layers.RnnOutputLayer",
"activationFn" : {
"@class" : "org.nd4j.linalg.activations.impl.ActivationSoftmax"
},
"biasInit" : 0.0,
"biasUpdater" : null,
"constraints" : null,
"dist" : null,
"gradientNormalization" : "None",
"gradientNormalizationThreshold" : 1.0,
"hasBias" : true,
"idropout" : null,
"iupdater" : {
"@class" : "org.nd4j.linalg.learning.config.RmsProp",
"epsilon" : 1.0E-8,
"learningRate" : 0.001,
"rmsDecay" : 0.95
},
"l1" : 0.0,
"l1Bias" : 0.0,
"l2" : 0.0,
"l2Bias" : 0.0,
"layerName" : "layer3",
"lossFn" : {
"@class" : "org.nd4j.linalg.lossfunctions.impl.LossMCXENT",
"softmaxClipEps" : 1.0E-10,
"configProperties" : false,
"numOutputs" : -1
},
"nin" : 100,
"nout" : 23,
"pretrain" : false,
"weightInit" : "XAVIER",
"weightNoise" : null
},
"maxNumLineSearchIterations" : 5,
"miniBatch" : false,
"minimize" : true,
"optimizationAlgo" : "STOCHASTIC_GRADIENT_DESCENT",
"pretrain" : false,
"seed" : 123,
"stepFunction" : null,
"variables" : [ ]
} ],
"epochCount" : 0,
"inferenceWorkspaceMode" : "ENABLED",
"inputPreProcessors" : { },
"iterationCount" : 0,
"pretrain" : false,
"tbpttBackLength" : 20,
"tbpttFwdLength" : 20,
"trainingWorkspaceMode" : "ENABLED"
}
Training Data
We generate the training data as array of all encoded input characters with their corrsponding encoded output which is just the subsequent character. E.g for the inptut ‘A’ we use the output (label) ‘ ‘.
// create input and output arrays: SAMPLE_INDEX, INPUT_NEURON,
// learnString
var input = Nd4j.zeros(1, charList.size, learnString.size);
var labels = Nd4j.zeros(1, charList.size, learnString.size);
// loop through our sample-sentence
for (samplePos <- 0 to learnString.size - 1) {
// small hack: when currentChar is the last, take the first char as
// nextChar - not really required. Added to this hack by adding a starter first character.
var currentChar = learnString(samplePos);
// On the last character we point back to the first character as next position
var nextChar = learnString((samplePos + 1) % (learnString.length));
// input neuron for current-char is 1 at "samplePos"
input.putScalar(Array[Int](0, charList.indexOf(currentChar), samplePos ), 1);
// output neuron for next-char is 1 at "samplePos"
labels.putScalar(Array[Int](0, charList.indexOf(nextChar), samplePos ), 1);
}
var trainingData = new DataSet(input, labels);
===========INPUT===================
[[[ 0, 0, 0 ... 0 0, 0],
[ 1.0000, 0, 0 ... 0 0, 0],
[ 0, 0, 0 ... 1.0000 0, 0],
...,
[ 0, 0, 0 ... 0 0, 0],
[ 0, 0, 0 ... 0 0, 0],
[ 0, 0, 0 ... 0 1.0000, 0]]]
=================OUTPUT==================
[[[ 0, 0, 0 ... 0 0, 0],
[ 0, 0, 0 ... 0 0, 1.0000],
[ 0, 0, 0 ... 0 0, 0],
...,
[ 0, 0, 0 ... 0 0, 0],
[ 0, 0, 0 ... 0 0, 0],
[ 0, 0, 0 ... 1.0000 0, 0]]]
Please note that both the features and labels are stored in a 3 dimensions tensor with the following size:
println("Size of Dimension 0 (time series): "+trainingData.getFeatures().size(0))
println("Size of Dimension 1 (values per time step): "+trainingData.getFeatures().size(1))
println("Size of Dimension 2 (time steps): "+trainingData.getFeatures().size(2))
Size of Dimension 0 (time series): 1
Size of Dimension 1 (values per time step): 23
Size of Dimension 2 (time steps): 101
null
Training UI
So that we can follow the leaning in the GUI we do the following:
– we set up the UIServer
– and show the UIServer in an IFrame
– we define the StatsListener to update the UI
– and finally start the learing
//Initialize the user interface backend
var uiServer = UIServer.getInstance();
//Configure where the network information (gradients, score vs. time etc) is to be stored. Here: store in memory.
var statsStorage = new InMemoryStatsStorage(); //Alternative: new FileStatsStorage(File), for saving and loading later
//Attach the StatsStorage instance to the UI: this allows the contents of the StatsStorage to be visualized
uiServer.attach(statsStorage)
"The server is available at http:/"+uiServer.getAddress()
The server is available at http://0.0.0.0:9000
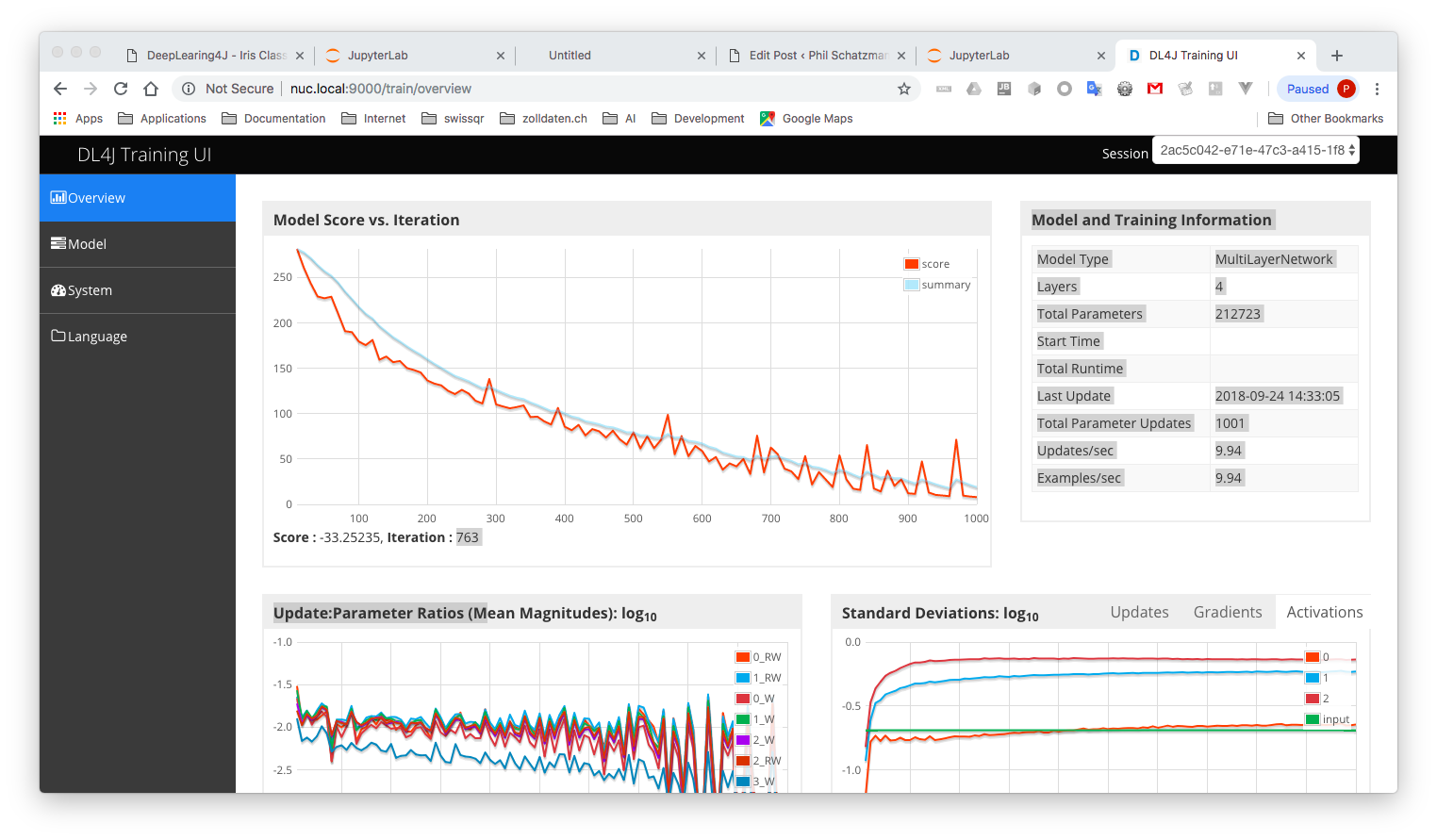
The score is the output of the loss function. The goal of the learning is to minimize the loss: so a smaller number is better as a bigger. We are looking for a situation the Model Score vs Iteration shows a steadily decreasing falling line.
net.init();
// add the StatsListener to collect this information to display in the UI
net.setListeners(new StatsListener(statsStorage))
val epochs = 1000
for (epoch <- 0 to epochs) {
// train the data
net.fit(trainingData);
}
"Training done!"
Training done!
Displaying the Result
The result can be determined with the help of the rnnTimeStep method. For the first call we pass the encoded start character * and get a matrix as result.
// clear current stance from the last example
net.rnnClearPreviousState();
// put the first character into the rrn as an initialisation
var testInit = Nd4j.zeros(1, charList.size, 1)
var pos:Int = charList.indexOf(learnString(0))
testInit.putScalar(pos, 1)
// run one step -> IMPORTANT: rnnTimeStep() must be called, not
// output(). The output shows what the net thinks what should come next
var output = net.rnnTimeStep(testInit);
[[0.0008,
0.0013,
0.0007,
0.0005,
0.0012,
0.0029,
0.0010,
0.0007,
0.8118,
0.0011,
0.0022,
0.0007,
0.1530,
0.0009,
0.0007,
0.0013,
0.0004,
0.0122,
0.0012,
0.0007,
0.0015,
0.0023,
0.0010]]
The resulting character can be determined from the maximum value in the array. Here it is the 9.th position with the value of 0.8118. If we check in our charList – the 9.th position contains the character ‘A’ !
The result matrix is then the input for the next call….
// now the net should guess LEARNSTRING.length more characters
var result = ""
for (char <- learnString) {
// first process the last output of the network to a concrete
// neuron, the neuron with the highest output has the highest
// chance to get chosen
var sampledCharacterIdx = Nd4j.getExecutioner().exec(new IMax(output), 1).getInt(0);
// concatenate the chosen output
result += charList(sampledCharacterIdx);
// use the last output as input
var nextInput = Nd4j.zeros(1, charList.size, 1);
nextInput.putScalar(sampledCharacterIdx, 1);
output = net.rnnTimeStep(nextInput);
}
result
A computer will do what you tell it to do, but that may be much different from what you had in mind.*

1 Comment
Anonymous · 24. November 2023 at 10:00
On my local CPU, 20 characters means at least 2 minutes of learning time with 1000 epochs (even with
.dataType(DataType.FLOAT)), and LTSM not having great result at generating text with tiny trainings.
Haven’t tried on GPU (CUDA) yet.